深入解析 RNS-CKKS 中的高效密钥切换:Hybrid Approach 原理与推导
在全同态加密(FHE)的硬件加速与软件库实现(如 Lattigo, OpenFHE)中,密钥切换(Key-Switching / Relinearization) 往往是性能的最主要瓶颈。
在 RNS-CKKS 方案中,如何高效地处理密钥切换一直是一个核心难题。从最早的两种朴素实现(Type I 和 Type II),发展到如今被广泛采用的 Hybrid Approach(混合方法),其背后的数学直觉与工程权衡非常精彩。
本文将详细剖析 论文《Efficient Bootstrapping for Approximate Homomorphic Encryption with Non-Sparse Keys》中 Hybrid Approach 的数学原理,给出严谨的正确性证明,并对比其与传统方法的优劣,特别适合正在进行 FHE GPU/ASIC 加速器开发的开发者阅读。
1. 背景:Key-Switching 的核心矛盾
在 CKKS 中,密文乘法后会得到一个三元密文 ,其解密形式包含 项:。为了让密文继续保持“由同一个秘密钥 解密”的形态,我们需要将其重线性化/密钥切换回二元密文 ,使得 。这一过程使用评估密钥(Switching Key / Relinearization Key),其计算核心可以理解为:对 (以及其分解后的 digits)与 做内积累加,从而“吸收”掉 项。
如果将其误实现为“直接同态计算密文与秘密钥的乘法”,会引入不可控的噪声放大并破坏正确性。工程实现中,为了在 RNS 下稳定地完成上述内积与后续的 ModDown,通常需要引入辅助模数 。
在 Hybrid Approach 出现之前,存在两种极端的处理流派:
- Type I (Bit/Digit Decomposition):将密文切得非常碎(例如按 RNS 素数切分)。
- 优点:不需要辅助模数 ,或 很小。
- 缺点:计算量极大(需要做 次 NTT 和乘法),存储开销大。
- Type II (Modulus Raising):不切分,直接引入一个巨大的辅助模数 ()。
- 优点:计算次数最少(只需 1 次乘法)。
- 缺点:参数爆炸。由于 ,总模数 翻倍,迫使多项式度数 升级(例如从 升至 ),导致整体性能雪崩。
Hybrid Approach 的诞生,就是为了在“计算复杂度”和“参数大小”之间寻找一个最佳甜点(Sweet Spot)。
2. Hybrid Approach 的核心思想
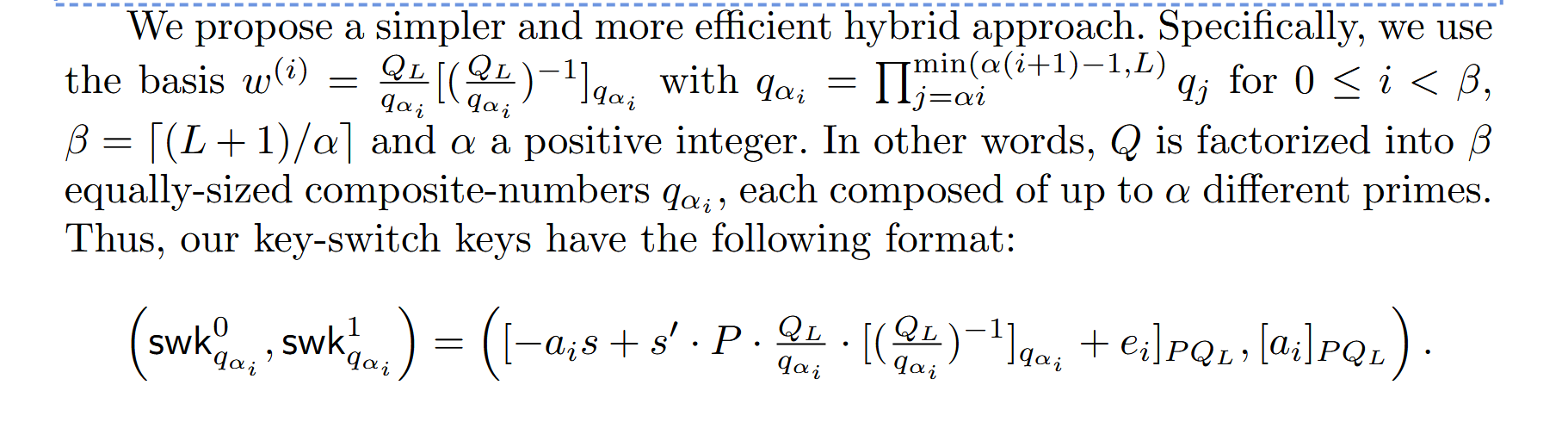

Hybrid Approach 引入了一个分解因子 (在部分文献中记为 )。它将模数链 分解为 个分块(Digits)。
- 适度的分解:我们不像 Type I 那样切成几十块,也不像 Type II 那样完全不切,而是切成 块。
- 适度的 :由于进行了分解,辅助模数 只需要大于分块的大小即可(即 )。这成功避免了总模数 的过度膨胀。
2.1 密钥结构
为了支持这种分解,我们利用 中国剩余定理(CRT) 构造了一组特殊的基底 。 Key-Switching Key () 被定义为 个密文的集合:
其中 是针对第 个分块的 CRT 基底。
3. 数学原理与正确性证明 (详细推导)
很多开发者对 Hybrid Approach 的困惑在于:为什么把密文切开再乘,最后还能加回去,且噪声还能被消除? 下面我们通过严谨的代数推导来证明其正确性。
3.1 预备定义
- :模 的多项式环。
- 分解:将 分解为 个分量 ,其中 仅在第 个分块的素数基中有值。
- CRT 基底 的定义: 关键性质:CRT 重构性质保证了 。即在整数环上,存在多项式 ,使得:
3.2 推导过程
算法的核心步骤包含:扩展、内积、ModDown。
步骤 1:内积运算 (Inner Product)
我们在模 下计算密文分量与密钥的内积:
注意:这里的 指的是通过 BConv 将 从其原本的小素数基扩展到整个 模数链后的结果。
让我们观察解密后的相位 (Phase):
步骤 2:提取公因式与 CRT 重构
将上式展开:
利用 3.1 中的 CRT 关键性质 ,代入上式:
步骤 3:模数 的魔法 (消除 kQ)
请注意加粗项 。 因为该项包含因子 和 ,它必然是 的倍数。 在 的环中,该项恒等于 0。
因此,内积的结果简化为:
步骤 4:Modulus Down (除以 P)
最后一步是 RNS 下的 Modulus Down,其数学意义是乘以 :
解密结果为:
结论:
- 正确性:我们成功还原了 。
- 噪声控制:总噪声 被巨大的辅助模数 除掉了。只要 足够大(),剩余噪声 就可忽略不计。
4. 深度剖析:Algorithm 3 的数据流向与 RNS 陷阱
在阅读相关文献(如 SHARP 论文或 Lattigo 源码)时,Algorithm 3 的第一行往往是最容易产生误解的地方。为了确保在 GPU/ASIC 上正确实现,需要结合 RNS 的算术特性,对数据流向进行严格的剖析。

4.1 核心结论:全模数扩展
观察算法第 1 行的公式:
这里表达了一个至关重要的实现细节:第一步生成的向量 ,其每一个分量都必须被扩展到完整的模数链 上,而不仅仅是 。
为什么?这是由 RNS 的乘法铁律 决定的:两个多项式要相乘,它们必须定义在“完全相同”的 RNS 基(素数集合)上。
4.2 详细原理解析
让我们拆解这一过程:
-
内层操作(分解) :
把密文 切成 个小块(Digits)。第 个小块 初始时刻只存在于它自己的素数基 中。
-
外层操作(扩展) :
这是完全扩展 (Full BConv)。需要把每一个小块 ,通过 BConv 扩展到整个当前的模数系统 (即 的所有素数 + 辅助模数 )。
为什么要扩展到整个 ?(而不是只扩展到 P)
这对应了算法 Line 2 的点积操作:
展开来看,其本质是求和:
请注意 Key () 的形态:
-
是预计算好的密钥,它必须存储在所有模数 () 上。因为它包含 这种项,且为了后续能正确 ModDown 回 ,它必须在整个 上也有定义。
-
RNS 对齐限制:在计算设备上执行
Mult(A, B)时,如果 A 只有 3 个 limb (mod ),而 B 有 5 个 limb (mod ),是无法进行点乘的。数据必须在维度上完全对齐。
因此,虽然 原本只在 上有值,但为了和“全尺寸”的 相乘,它必须被 BConv 投影到 所在的所有素数上。
4.3 修正后的完整数据流 (Step-by-Step)
假设 ,,。
Digit 0 是 ,Digit 1 是 。
-
Step 1: 分解与全扩展 (Algorithm 3, Line 1)
-
从密文 中切出第一块 (在 上)。
-
关键修正:需要计算 在 上的投影。
-
误区提示: 不是在 上填 0!
-
正确做法: 是一个整数多项式,它在 mod 下有具体的非零值。需要通过 INTT (在 ) -> BConv -> NTT (在 ) 算出来。
-
-
最终,得到一个“胖”的 ,它在 上都有值。
-
同理处理 ,得到“胖”的 。
-
-
Step 2: 内积 (Line 2)
-
计算 (全模数链乘法)。
-
计算 (全模数链乘法)。
-
相加得到结果 (在 上)。
-
-
Step 3: ModDown (Line 3)
-
现在 在 上。
-
执行标准的 ModDown 流程:取 分量 扩展回 相减 乘 丢弃 。
-
4.4 理论直觉与 RNS 实现的差异
为什么容易产生“填 0”或“只扩展到 P”的误解?这是因为混淆了 CRT 基底的理论性质 和 RNS 的具体实现。
-
理论上:如果看的是 这个公式,CRT 基底 在其他 (非当前 digit)下确实是 。
-
实际上:Algorithm 3 不是 直接构造 。它是把 当作一个独立的数,去乘 。而 内部隐含了 。为了执行这个乘法,数据必须对齐到全模数。
4.5 针对 GPU 实现的建议
基于上述分析,在 28-bit GPU 实现中,应当构建以下三个核心 Kernel:
-
Kernel 1 (Full BConv): 实现一个能够将 个小块,分别广播/扩展到整个模数链 的 Kernel。这会是计算密集度很高的一步,复杂度为 。
-
Kernel 2 (MultAcc): 在全模数链 上执行点积累加。
-
Kernel 3 (ModDown): 再次调用 BConv 把 上的结果投影回 ,然后做减法。
5. 对比与权衡 (Trade-off)
为什么 Hybrid Approach 能够胜出?以下是三种方案的详细对比:
| 特性 | Type I (Bit Decomposition) | Type II (Modulus Raising) | Hybrid Approach (Sweet Spot) |
|---|---|---|---|
| 分解数量 () | (约 20~60) | 2 ~ 4 | |
| 辅助模数 大小 | 不需要或很小 | (巨大) | (适中) |
| 总模数 | |||
| 密钥存储 (swk) | 个 | 1 个 | 个 |
| 计算复杂度 | 极高 ( 次乘法) | 低 (1 次大乘法) | 中等 ( 次乘法) |
| 参数安全性 | 优秀 | 差 (易导致 N 翻倍) | 优秀 (保持小 N) |
分析结论
-
为什么不用 Type II? 虽然 Type II 只需要存 1 个 Key,算 1 次乘法,看似最快。但由于 ,导致总模数 极大。为了满足同态加密的安全性(128-bit Security),更大的模数要求更大的多项式度数 。 一旦 从 被迫增加到 ,计算延迟会增加 2-4 倍,内存占用翻倍。这是得不偿失的。
-
为什么 Hybrid 是最优解? Hybrid 通过设置 ,使得 只有 的三分之一大小。这样 的总大小通常能维持在当前 的安全范围内。 虽然我们需要存储 3 个 Key,多做几次 BConv,但相比于 翻倍带来的性能损耗,这些开销是完全可以接受的。
-
显存带宽优化 针对 GPU 实现,存储 个 Key 可能会占用大量带宽。SHARP 论文和现代库建议使用 PRNG (伪随机数生成器):
- 。
- 其中多项式 是随机的。我们在显存中只存一个 32字节的 Seed。
- 在计算时,GPU 动态生成 ,从而将带宽占用减半。
6. 总结
Hybrid Approach 是 RNS-CKKS 密钥切换技术的集大成者。它利用 CRT 的代数性质,巧妙地化解了噪声与效率的矛盾。
对于硬件开发者而言,理解其背后的 “扩展 -> 内积 -> 模约减” 这一 RNS 数据流至关重要。正确实现 Hybrid Approach,并配合 的参数调优,是实现高性能 FHE 加速器的关键一步。